The purpose of this guide is to instruct the user in the basic concepts behind the CAS-Metadata project, including the basics of metadata, how to write metadata extractors, and explanations of existing metadata extractors. In addition to this guide, some of these concepts are also covered in our CAS-File Manager User Guide and in our CAS-Curator Basic User Guide. For advanced topics, including extracting techniques to allow for type-based matching, see our Advanced Guide. In the rest of this guide, we will cover the following topics:
Metadata is data about data. Simply put, metadata is information about data that aids the user in finding what they are looking for and clarifying what they are looking at. There are many examples of metadata standards, including Dublin Core and ISO Standards.
Examples of metadata include filename, URL, data producer, start and stop datetime for temporal files, bounding polygons for geo-referenced data, etc. In the CAS-Metadata project, and in all of OODT, Metadata Objects are considered a container for product-related metadata. Interfaces for the Metadata Object are shown below:
public class Metadata {
public Metadata() {...}
public Metadata(InputStream is) throws Exception {...}
public void addMetadata(Hashtable metadata) {...}
public void addMetadata(Hashtable metadata, boolean replace) {...}
public void replaceMetadata(Hashtable metadata) {...}
public void addMetadata(String key, String value) {...}
public void addMetadata(String key, List values) {...}
public void replaceMetadata(String key, List values) {...}
public void replaceMetadata(String key, String value) {...}
public Object removeMetadata(String key) {...}
public List getAllMetadata(String key) {...}
public String getMetadata(String key) {...}
public Hashtable getHashtable() {...}
public boolean containsKey(String key) {...}
public boolean isMultiValued(String key) {...}
public boolean equals(Object obj) {....}
public Document toXML() throws Exception {...}
private void parse(Document document) throws Exception {...}
}
The CAS-Metadata Metadata object is a key-multivalue container. Users can add metadata elements to the Metadata Object via InputStream, HashTable Object, key with an array of values, and a simple key and signal value interface. All keys and values are represented as Strings. See our Advanced Guide for more information about the ramification of this design decision during type-based metadata search and comparison.
In addition to the accessor and modifier methods that work with simple Strings, the Metadata Object can work with XML Documents. An example of metadata in the XML format is given below:
<cas:metadata xmlns:cas="http://oodt.jpl.nasa.gov/1.0/cas">
<keyval>
<key>ProductType</key>
<val>MP3</val>
</keyval>
<keyval>
<key>Filename</key>
<val>blue_suede_shoes.mp3</val>
</keyval>
<keyval>
<key>Artist</key>
<val>The Beatles</val>
</keyval>
<keyval>
<key>Album</key>
<val>Revolver</val>
</keyval>
<keyval>
<key>SongName</key>
<val>Blue Suede Shoes</val>
</keyval>
</cas:metadata>The above metadata example has been extracted from an MP3 file. There are a number of metadata elements, including the Artist, Album, and SongName, as well as the product type (in this case, 'MP3'), and the name of the mp3 file. In addition, metadata elements can be multivalued. In this case, the <keyval> element can have multiple <val> child elements.
The role of a metadata extractor is extract metadata from one or more product types. In order to extract metadata, the extractor must understand the product type format, parse the product, and return metadata to be associated with the product. CAS-Curator, for example, uses metadata extractors to generate metadata for products in its staging area, both as a preview to the curator, and also during the course of data ingestion.
The CAS-Metadata project contains an interface class, org.apache.oodt.cas.metadata.MetExtractor. This API consists of two primary methods (with multiple method signatures each). This API can be seen below:
public interface MetExtractor {
public Metadata extractMetadata(File f)
throws MetExtractionException;
public Metadata extractMetadata(String filePath)
throws MetExtractionException;
public Metadata extractMetadata(URL fileUrl)
throws MetExtractionException;
public Metadata extractMetadata(File f, File
configFile) throws MetExtractionException;
public Metadata extractMetadata(File f, String
configFilePath) throws MetExtractionException;
public Metadata extractMetadata(File f,
MetExtractorConfig config)
throws MetExtractionException;
public Metadata extractMetadata(URL fileUrl,
MetExtractorConfig config)
throws MetExtractionException;
public void setConfigFile(File f)
throws MetExtractionException;
public void setConfigFile(String filePath)
throws MetExtractionException;
public void setConfigFile(MetExtractorConfig config);
}In order to implement a new extractor, a developer may implement the MetExtractor interface, or develop a metadata extractor that adheres to this interface in the development language of choice.
The CAS-Metadata project contains a number of existing metadata extractor implementations that the develop can directly leverage.
There are many situations in which developers are interested in using a metadata extractor that is not written in Java. Perhaps there is an existing extractor written in a different programming language the source of which you do not have access, or perhaps there are functional or non-functional requirements that make a different language more appropriate.
We have developed the ExternMetExtractor as part of the CAS Metadata project to address this issue. The ExternMetExtractor uses a configuration file to specify the extractor working directory, the path to the executable, and any commandline arguments. This configuration file is specified below:
<?xml version="1.0" encoding="UTF-8"?>
<cas:externextractor xmlns:cas="http://oodt.jpl.nasa.gov/1.0/cas">
<exec workingDir="">
<extractorBinPath envReplace="true">[PWD]/extractor</extractorBinPath>
<args>
<arg isDataFile="true"/>
<arg isPath="true">/usr/local/etc/testExtractor.config</arg>
</args>
</exec>
</cas:externextractor>There are a number of important elements to the external metadata extractor configuration file, including working directory (the workingDir attribute on the exec tag), the path the the executable extractor (the value of the extractorBinPath tag), and any arguments required by the extractor (values of the args tags).
The working directory (the directory in which the metadata file is to be generated), is assumed to be the directory in which the extractor is run. This is signaled by a null value.
Command-line arguments are delivered to the external extractor in the order they are listed in the configuration file. In order words,
<args>
<arg>arg1</arg>
<arg>arg2</arg>
<arg>arg3</arg>
</args>
would be passed to the extractor as arg1 arg2 arg3.
Additionally, there are a number of specializations of the arg tag that can be set with tag attributes. Specifically:
For an example of the use of this type of metadata extractor, we our CAS-Curator Basic User Guide.
In many cases, products that are to be ingested are named with metadata that should be extracted from the product name and cataloged upon ingest. For this type of situation, we have developed the FilenameTokenMetExtractor. This extractor uses a configuration file that specifies, for each metadata element, the index of the start position in the name for this metadata and its character length.
Below is an example configuration file used by the FilenameTokenMetExtractor. It assumes a product name formatted as follows:
MissionName_Date_StartOrbitNumber_StopOrbitNumber.txt
<input>
<group name="SubstringOffsetGroup">
<vector name="MissionName">
<element>1</element>
<element>11</element>
</vector>
<vector name="Date">
<element>13</element>
<element>4</element>
</vector>
<vector name="StartOrbitNumber">
<element>18</element>
<element>16</element>
</vector>
<vector name="StopOrbitNumber">
<element>35</element>
<element>15</element>
</vector>
</group>
<group name="CommonMetadata">
<scalar name="DataVersion">1.0</scalar>
<scalar name="CollectionName">Test</scalar>
<scalar name="DataProvider">OODT</scalar>
</group>
</input>
In this configuration, the FilenameTokenMetExtractor will produce four metadata elements from the product name: MissionName, Date, StartOrbitNumber, and StopOrbitNumber. The first element of each of these groups is the start index (this assumes 1-indexed strings). The second element is the substring length.
Additionally, this configuration specifies that metadata for all products additionally contain three comment metadata elements that are static: DataVersion, CollectionName, and DataProvider.
The ProdTypePatternMetExtractor can also be used to extract metadata from the filename. Unlike the FilenameTokenMetExtractor, metadata elements do not have to be fixed-offset and fixed-length. Instead, metadata elements are represented by regular expressions. These elements are used in filename templates that, when matched, dynamically determine the ProductType of the file.
Below is an example of a product-type-patterns.xml configuration file used by the ProdTypePatternMetExtractor:
<config>
<!-- <element> MUST be defined before <product-type> so their patterns can be resolved -->
<!-- name MUST be an element defined in elements.xml (also only upper and lower case alpha chars) -->
<!-- regexp MUST be valid input to java.util.regex.Pattern.compile() -->
<element name="ISBN" regexp="[0-9]{10}"/>
<element name="Page" regexp="[0-9]*"/>
<!-- name MUST be a ProductType name defined in product-types.xml -->
<!-- metadata elements inside brackets MUST be mapped to the ProductType,
as defined in product-type-element-map.xml -->
<product-type name="Book" template="book-[ISBN].txt"/>
<product-type name="BookPage" template="page-[ISBN]-[Page].txt"/>
</config>
This file defines a regular expression for the "ISBN" metadata element, in this case, a 10-digit number. Also, the "Page" metadata element is defined as a sequence of 0 or more digits.
Next, the file defines a filename pattern for the "Book" product type. The pattern is compiled into a regular expression, substituting the previously defined regexes as capture groups. For example, "book-[ISBN].txt" compiles to "book-([0-9]{10}).txt", and the ISBN met element is assigned to capture group 1. When the filename matches this pattern, 2 metadata assignments occur: (1) the ISBN met element is set to the matched regex group, and (2) the ProductType met element is set to "Book". Similarly, the second pattern sets ISBN, Page, and ProductType for files matching "page-([0-9]{10})-([0-9]*).txt". This achieves several things:See the JavaDoc for more detailed information about using the ProdTypePatternMetExtractor
The MetReaderExtractor, part of the OODT CAS-Metadata project, assumes that a metadata file with then nameing convention "<Product Name>.met" is present in the same directory as the product. This extractor further assumes that the metadata is in the format specified in this document.
The CopyAndRewriteExtractor is a metadata extractor, that, like the MetReaderExtractor, assumes that a metadata file exists for the product from which metadata is to be extracted. This extractor reads in the original metadata file and replaces particular metadata values in that metadata file.
The CopyAndRewriteExtractor takes in a configuration file that is a java properties object with the following properties defined:
An example of the configuration file is given below:
numRewriteFields=2 rewriteField1=ProductType rewriteField2=FileLocation orig.met.file.path=./src/resources/examples/samplemet.xml ProductType.pattern=NewProductType[ProductType] FileLocation.pattern=/new/loc/[FileLocation]
In ths example configuration, two metadata elements will be rewritten, ProductType and FileLocation. The original metadata file is located on at ./src/resources/examples/samplemet.xml. The Product Type will be rewritten as NewProductType<original ProductType value>. The File location will now be set to /new/location./src/resources/examples/samplemet.xml.
The most common use-case of CAS-Metadata is to capture the output of a metadata extractor for use in the CAS-Filemgr's ingestion process.
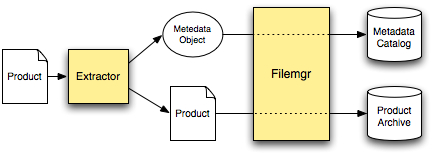
In the above diagram, a metadata object is producted by an extractor. The product and its associated metadata are both ingested into the CAS-Filemgr. The metadata will go into the Filemgr's metadata catalog and the product will go to the archive.
Because metadata extractors and the CAS-Filemgr are not tightly-coupled, there are a number of implicit design assumptions that effect how you design metadata extractors in this use-case. For example, CAS-Filemgr differentiates between products based on product type. File type and product type are not necessarily identical, so you should write extractors to to produce metadata specific to product types (See the Advanced Guide for information on mime-type detection).
Along the same lines, remember that there is no mechanism to enforce the metadata extracted for a particular product type be ingested into the Filemgr's catalog. The command-line ingest client for the CAS-Filemgr is given below (note that the command-line interface and the API are equivelent):
filemgr-client --url <url to xml rpc service> --operation \ --ingestProduct --productName <name> --productStructure <Hierarchical|Flat> --productTypeName <name of product type> --metadataFile <file> \ [--clienTransfer --dataTransfer <java class name of data transfer factory>] \ --refs <ref1>...<refn>
In the above interface, the important feature to note is that the user supplies not only the product, but also the metadata file (or Metadata Object in the case of the API), the Product Name, Structure and Type on ingest. Since each of these pieces of information is independant, it is the user's responsibility to maintain consistancy of the product type metadata between the extraction process and the ingest process.
This is intended to be a basic guide to users of the CAS-Metadata project. We have purposely omitted the discussion of metadata stardards, though we strongly encourage you to investigate the role of standards and ontology in your particular application. In our Advanced Guide, we cover more topics regarding the nuences of metadata extraction, including the impact of String-based representation on metadata element comparisons.
