Apache Object Oriented Data Technology (OODT) is the smart way to integrate and archive your processes, your data, and its metadata. OODT allows you to:
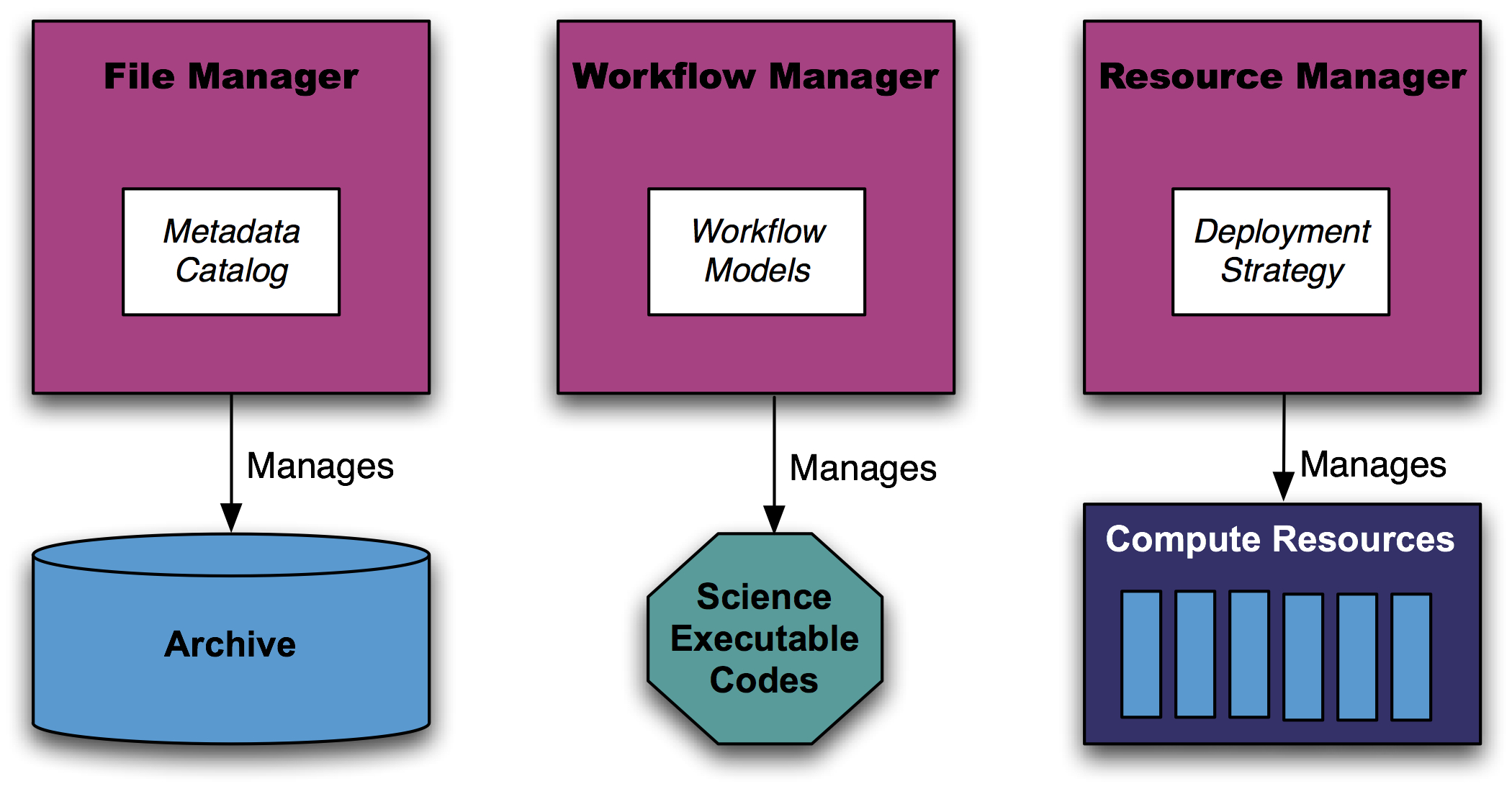
Traditional processing pipelines are commonly made up of custom UNIX shell scripts and fragile custom written glue code. Apache OODT uses structured XML-based capturing of the processing pipeline that can be understood and modified by non-programmers to create, edit, manage and provision workflow and task execution.
OODT also allows for remote execution of jobs on scalable computational infrastructures so that computational and data-intensive processing can be integrated into OODT’s data processing pipelines using cloud computing and high-performance computing environments.
Having awarded in 2003 as the NASA Software of the Year, Apache Object Oriented Data Technology (OODT) began at the Jet Propulsion Laboratory, in operations cataloging pictures of Mars and helping to detect cancer. Apache OODT is smart, open source software for science, research, or otherwise.
Apache OODT is the superior way to integrate and archive your processes, your data, and its metadata. It spans scientific and other disciplines and enable interoperability among data agnostic systems in the varying fields. Using OODT's framework of distributed objects and databases, the data collected by scientists and engineers in disparate disciplines can be jointly searched, stored, retrieved, and analyzed. It facilitates the creation, acquisition, and growth of data management and archiving systems.
Processing pipelines are too often one-off custom solutions that fail to scale and evolve as systems evolve. Moreover, archived data undergoes a kind of atrophy as the tools used to analyze and process it are themselves one-off solutions with no maintenance. These haphazard approaches achieve only short term success, but are not effective in data search, discovery, analysis, cataloging, processing, or archiving. OODT replaces these manual, forgettable steps with reliable workflows through distributed data grids. OODT ensures the usability and value of data even after original developers move on.
Haphazard processing pipelines are commonly made up of custom UNIX shell scripts and/or fragile custom written glue code of Java, Python, and Perl. OODT uses structured XML-based capturing of the processing pipeline that can be understood and modified by non-programmers to create, edit, manage and provision workflow and task execution.
Apache OODT facilitates the integration of highly distributed and heterogeneous data intensive systems enabling the integration of different, distributed software systems, metadata and data. OODT spans disciplines and enables interoperability among data agnostic systems in any field.
In a world of cloud computing Apache OODT can make the most of it. With support for: