This is the user guide for the OODT Catalog and Archive Service (CAS) Crawler Framework, or CAS Crawler for short. This guide explains the CAS Crawler architecture including its extension points. The guide also discusses available services provided by the CAS Crawler, how to utilize them, and the different APIs that exist. The guide concludes with a description of CAS Crawler use cases.
The CAS Crawler Framework represents an effort to standardize the common ingestion activities that occur in data acquisition and archival. These types of activities regularly involve identification of files and directories to crawl (based on e.g., mime type, regular expressions, or direct user input), satisfaction of ingestion pre-conditions (e.g., the current crawled file has not been previously ingested), followed by metadata extraction. After metadata extraction, crawled data follows a standard three state lifecycle:
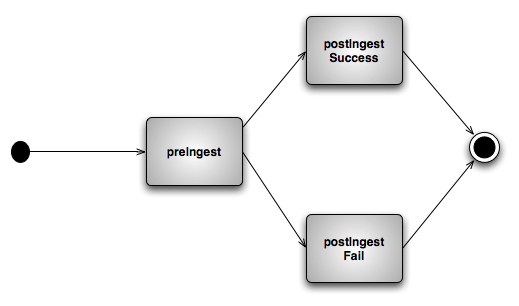
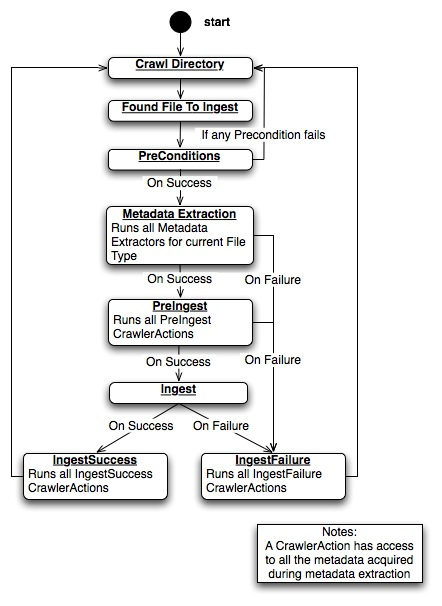
The critical objects managed by the CAS Crawler framework include:
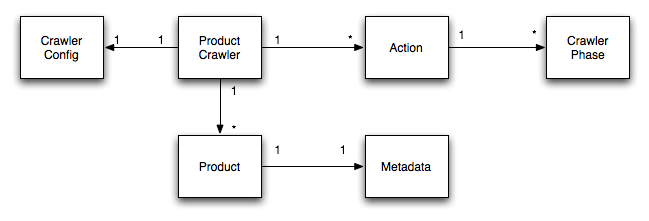
Each Product Crawler is configured by exactly one Crawler Config. Each Product Crawler has 1...* Crawler Actions which are each associated with 1...* Crawler Phases. Each Product Crawler crawls 1...* Products, which are each associated with exactly 1 Metadata object. These relationships are shown in the below figure.
There are several extension points for the Crawler Framework. An extension point is an interface within the crawler framework that can have many implementations. This is particularly useful when it comes to software component configuration because it allows different implementations of an existing interface to be selected at deployment time. So, the crawler framework may leverage a preIngest action that checks against a Crawler Framework Catalog to determine if a Product has already been ingested, or the crawler may choose a preIngest action that performs an MD5 checksum on the Product before ingesting. The selection of the actual component implementations is handled entirely by the extension point mechanism. Using extension points, it is fairly simple to support many different types of what are typically referred to as "plug-in architectures" Each of the core extension points for the Crawler Framework is described below:
| Crawler Daemon | The Crawler Daemon extension point is responsible for periodically (as defined by the User) executing a particular ProductCrawler, as well as providing statistics on crawls (number of crawls, average crawl time, etc.). |
| Product Crawler | The Product Crawler extension point is responsible for defining the method in which Crawler Preconditions are checked before ingestion, for managing the 3-phase ingestion process, and for dictating the method by which Metadata is obtained for a particular product. In addition, the extension point also specifies how Product files are crawled on disk. |
| Mime Type Extractor Repository | The Mime Type Extractor Repository is an extension point that specifies how Met Extractors are associated with mime types related to a Product file being ingested. |
| Crawler Action Repository | The Crawler Action Repository is a home for all Crawler Actions, mapping each Action to a lifecycle phase (preIngest, postIngestSuccess, or postIngestFailure). |
| Precondition Comparator | The Precondition Comparator extension point allows for the specification of preconditions that must be satisfied before metadata is extracted for a particular crawled Product, and ultimately which must be satisfied before ingestion. |
| Met Extractor, Met Extractor Config, Met Extractor Config Reader | The Crawler Framework leverages CAS Metadata's Met Extractor, Met Extractor Config, and Met Extractor Config Reader extension point. Each Met Extractor is provided a Met Extractor Config file, which is read by an associated Met Extractor Config Reader, allowing a User to entirely customize how Metadata is extracted for a particular Product file. |
The relationships between the extension points for the Crawler Framework are shown in the below figure.
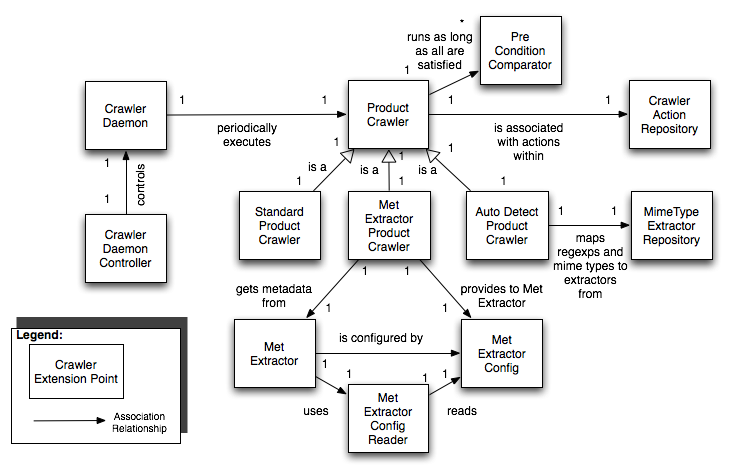
The Crawler Framework is responsible for providing the necessary key capabilities for manually and automatically ingesting files and metadata. Each high level capability provided by the Crawler Framework is detailed below:
This capability set is not exhaustive, and is meant to give the user a "feel" for what general features are provided by the Crawler Framework. Most likely the user will find that the Crawler Framework provides many other capabilities besides those described here.
There is at least one implementation of all of the aforementioned extension points for Crawler Framework. Each existing extension point implementation is detailed below:
To install the Crawler Framework, you need to download a release of the software, available from its home web site. For bleeding-edge features, you can also check out the cas-crawler trunk project from the Apache OODT subversion repository. You can browse the repository using ViewCVS, located at:
http://svn.apache.org/viewvc/oodt/The actual web url for the repository is located at:
https://svn.apache.org/repos/asf/oodtTo check out the Crawler Framework, use your favorite Subversion client.
The cas-crawler project follows the traditional Subversion-style trunk, tag and branches format. Trunk corresponds to the latest and greatest development on the cas-crawler. Tags are official release versions of the project. Branches correspond to deviations from the trunk large enough to warrant a separate development tree.
For the purposes of this the User Guide, we'll assume you already have downloaded a built release of the Crawler Framework, from its web site. If you were building cas-crawler from the trunk, a tagged release (or branch) the process would be quite similar. To build cas-crawler, you would need the Apache Maven software. Maven is an XML-based, project management system similar to Apache Ant, but with many extra bells and whistles. Maven makes cross-platform project development a snap. You can download Maven from: http://maven.apache.org/ All cas-crawler releases post 1.x.0 are now Maven 2 compatible. This is very important. That means that if you have any cas-crawler release > 1.x.0, you will need Maven 2 to compile the software, and Maven 1 will no longer work.
Follow the procedures in the below Sections to build a fresh copy of the Crawler Framework. These procedures are specifically targeted on using Maven 2 to build the software:
# mvn package
cas-crawler-${version}-dist.tar.gz
bin/ etc/ logs/ doc/ lib/ policy/ LICENSE.txt CHANGES.txt
To deploy the Crawler Framework, you'll need to create an installation directory. Typically this would be somewhere in /usr/local (on *nix style systems), or C:\Program Files\ (on windows style systems). We'll assume that you're installing on a *nix style system though the Windows instructions are quite similar.
Follow the process below to deploy the Crawler Framework:
# cp -R cas-crawler/trunk/target/cas-crawler-${version}-dist.tar.gz /usr/local/# cd /usr/local ; tar xvzf cas-crawler-${version}-dist.tar.gz# ln -s /usr/local/cas-crawler-${version} /usr/local/crawlerOther configuration options are possible: check the API documentation, as well as the comments within the XML files in the policy directory to find out the rest of the configurable properties for the extension points you choose. A full listing of all the extension point factory class names are provided in the Appendix. After step 4, you are officially done configuring the Crawler Framework for deployment.
To run the crawler_launcher, cd to /usr/local/crawler/bin and type:
# ./crawler_launcher -h
This will print the help options for the Crawler launcher script. Your Crawler Framework is now ready to run! You can test out the Crawler Framework by running a simple ingest command shown below. Be sure that a separate File Manager instance is up and running on the default port of 9000, running on localhost, before starting this test command (see the File Manager User Guide for more information). First create a simple text file called "blah.txt" and place it inside a test directory, e.g., /data/test. Then, create a default metadata file for the product, using the schema or DTD provided in the cas-metadata project. An example XML file might be:
<cas:metadata xmlns:cas="http://oodt.jpl.nasa.gov/1.0/cas">
<keyval>
<key>Filename</key>
<val>blah.txt</val>
</keyval>
<keyval>
<key>FileLocation</key>
<val>/data/test</val>
</keyval>
<keyval>
<key>ProductType</key>
<val>GenericFile</val>
</keyval>
</cas:metadata>
Call this metadata file blah.txt.met, and place it also in /data/test. Then, run the below command, assuming that you started a File Manager on localhost on the default port of 9000:
# ./crawler_launcher \
--crawlerId StdProductCrawler \
--productPath /data/test \
--filemgrUrl http://localhost:9000/ \
--failureDir /tmp \
--actionIds DeleteDataFile MoveDataFileToFailureDir Unique \
--metFileExtension met \
--clientTransferer org.apache.oodt.cas.filemgr.datatransfer.LocalDataTransferFactory
You should see a response message at the end similar to:
log4j:WARN No appenders could be found for logger (org.springframework.context.support.FileSystemXmlApplicationContext).
log4j:WARN Please initialize the log4j system properly.
http://localhost:9000/
StdProductCrawler
Jun 30, 2009 8:26:57 AM org.apache.oodt.cas.crawl.ProductCrawler crawl
INFO: Crawling /data/test
Jun 30, 2009 8:26:57 AM org.apache.oodt.cas.crawl.ProductCrawler handleFile
INFO: Handling file /data/test/blah.txt
Jun 30, 2009 8:26:57 AM org.apache.oodt.cas.metadata.extractors.MetReaderExtractor extrMetadata
INFO: Reading metadata from /data/test/blah.txt.met
Jun 30, 2009 8:26:57 AM org.apache.oodt.cas.crawl.ProductCrawler ingest
INFO: ProductCrawler: Ready to ingest product: [/data/test/blah.txt]: ProductType: [GenericFile]
Jun 30, 2009 8:26:57 AM org.apache.oodt.cas.filemgr.ingest.StdIngester setFileManager
INFO: StdIngester: connected to file manager: [http://localhost:9000/]
Jun 30, 2009 8:26:57 AM org.apache.oodt.cas.filemgr.datatransfer.LocalDataTransferer setFileManagerUrl
INFO: Local Data Transfer to: [http://localhost:9000/] enabled
Jun 30, 2009 8:26:57 AM org.apache.oodt.cas.filemgr.ingest.StdIngester ingest
INFO: StdIngester: ingesting product: ProductName: [blah.txt]: ProductType: [GenericFile]: FileLocation: [/data/test/]
Jun 30, 2009 8:26:57 AM org.apache.oodt.cas.filemgr.versioning.VersioningUtils createBasicDataStoreRefsFlat
FINE: VersioningUtils: Generated data store ref: file:/Users/mattmann/files/blah.txt/blah.txt from origRef: file:/data/test/blah.txt
Jun 30, 2009 8:26:57 AM org.apache.oodt.cas.filemgr.system.XmlRpcFileManager runExtractors
INFO: Running Met Extractor: [org.apache.oodt.cas.filemgr.metadata.extractors.CoreMetExtractor] for product type: [GenericFile]
Jun 30, 2009 8:26:57 AM org.apache.oodt.cas.filemgr.system.XmlRpcFileManager runExtractors
INFO: Running Met Extractor: [org.apache.oodt.cas.filemgr.metadata.extractors.examples.MimeTypeExtractor] for product type: [GenericFile]
Jun 30, 2009 8:26:57 AM org.apache.oodt.cas.filemgr.catalog.LuceneCatalog toDoc
WARNING: No Metadata specified for product [blah.txt] for required field [DataVersion]: Attempting to continue processing metadata
Jun 30, 2009 8:26:57 AM org.apache.oodt.cas.filemgr.system.XmlRpcFileManagerClient ingestProduct
FINEST: File Manager Client: clientTransfer enabled: transfering product [blah.txt]
Jun 30, 2009 8:26:57 AM org.apache.oodt.cas.filemgr.datatransfer.LocalDataTransferer moveFile
INFO: LocalDataTransfer: Moving File: file:/data/test/blah.txt to file:/Users/mattmann/files/blah.txt/blah.txt
Jun 30, 2009 8:26:57 AM org.apache.oodt.cas.filemgr.catalog.LuceneCatalog toDoc
WARNING: No Metadata specified for product [blah.txt] for required field [DataVersion]: Attempting to continue processing metadata
Jun 30, 2009 8:26:57 AM org.apache.oodt.cas.crawl.ProductCrawler ingest
INFO: Successfully ingested product: [/data/test/blah.txt]: product id: 72db4bba-658a-11de-bedb-77f2d752c436
Jun 30, 2009 8:26:57 AM org.apache.oodt.cas.crawl.ProductCrawler handleFile
INFO: Successful ingest of product: [/data/test/blah.txt]
Jun 30, 2009 8:26:57 AM org.apache.oodt.cas.crawl.ProductCrawler performProductCrawlerActions
INFO: Performing action (id = DeleteDataFile : description = Deletes the current data file)
Jun 30, 2009 8:26:57 AM org.apache.oodt.cas.crawl.action.DeleteFile performAction
INFO: Deleting file /data/test/blah.txt
Jun 30, 2009 8:26:57 AM org.apache.oodt.cas.crawl.ProductCrawler handleFile
INFO: Handling file /data/test/blah.txt.met
Jun 30, 2009 8:26:57 AM org.apache.oodt.cas.crawl.ProductCrawler handleFile
WARNING: Failed to pass preconditions for ingest of product: [/data/test/blah.txt.met]
which means that everything installed okay!
The Crawler Framework was built to support several of the above capabilities outlined in Section 3. In particular there were several use cases that we wanted to support, some of which are described below.
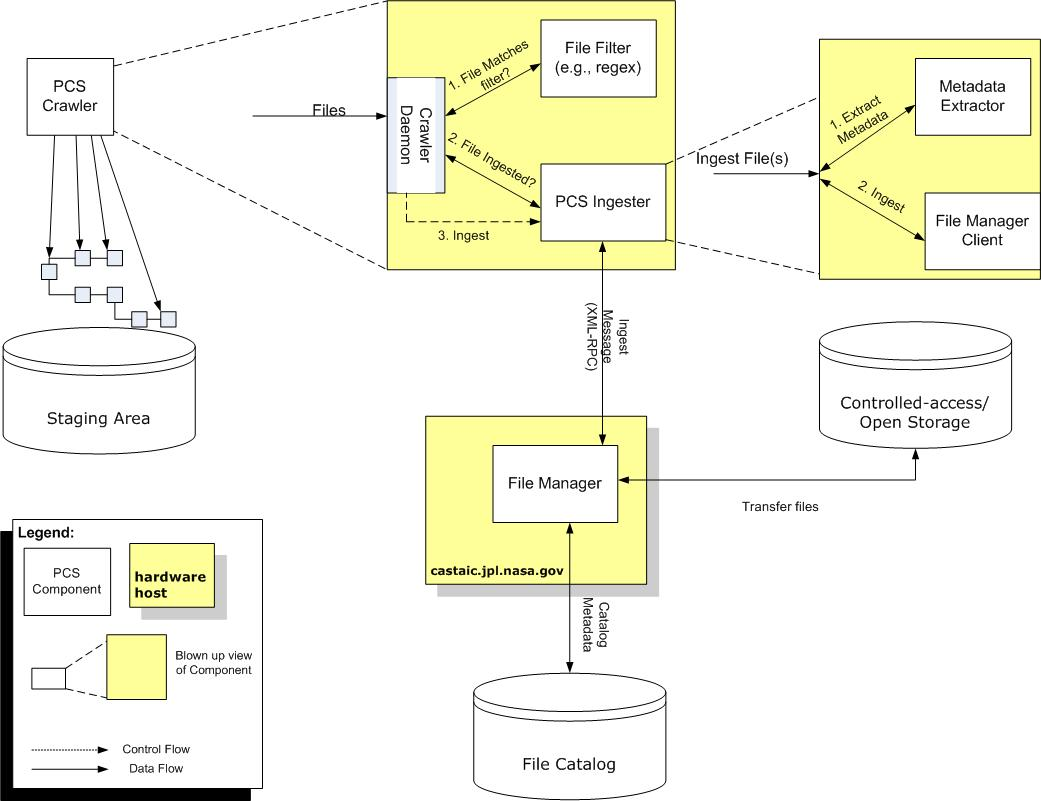
The numbers in the above Figure correspond to a sequence of steps that occurs and a series of interactions between the different Crawler Framework extension points in order to perform the file ingestion activity. In Step 1, the Crawler Daemon determines if the Product file in the staging area matches a specified File Filter regular expression. In step 2, if the Product file does match the desired filter, the Crawler Daemon checks with the File Manager (using the Ingester) to determine whether or not the Product file has been ingested. In step 3, assuming that the Product file has not been ingested, then the Crawler Daemon ingests the Product file into the File Manager using the Ingester interface. During the ingestion, Metadata is first extracted (in sub-step 1) and then the File Manager client interface is used (in sub-step 2) to ingest into the File Manager. During ingestion, the File Manager is responsible for moving the Product file(s) into controlled access-storage and cataloging the provided Product metadata.
Full list of Crawler Framework extension point classes and their associated property names from the Spring Bean XML files:
| actions | org.apache.oodt.cas.crawl.action.DeleteFile org.apache.oodt.cas.crawl.action.FilemgrUniquenessChecker org.apache.oodt.cas.crawl.action.MimeTypeCrawlerAction org.apache.oodt.cas.crawl.action.MoveFile org.apache.oodt.cas.crawl.action.WorkflowMgrStatusUpdate |
| preconditions | org.apache.oodt.cas.crawl.comparator.FilemgrUniquenessCheckComparator |
